裁剪:裁剪部 JHNY欧洲杯体育
【新智元导读】就在刚刚,Anthropic祭出首个混杂推理Claude 3.7 Sonnet,号称膨大念念考模式的最强模子。在最新编码测试中,新模子暴击o3-mini、DeepSeek R1,AI编码王者出世了。
憋了泰半年,Anthropic终于放出大招——首款混杂推理模子Claude 3.7 Sonnet重磅登场!
这是Claude系列中,迄今为止最智能的模子,确凿省略实时响应,并进行可膨大的、逐渐的念念考。

简言之,一个模子,两种念念考方式。
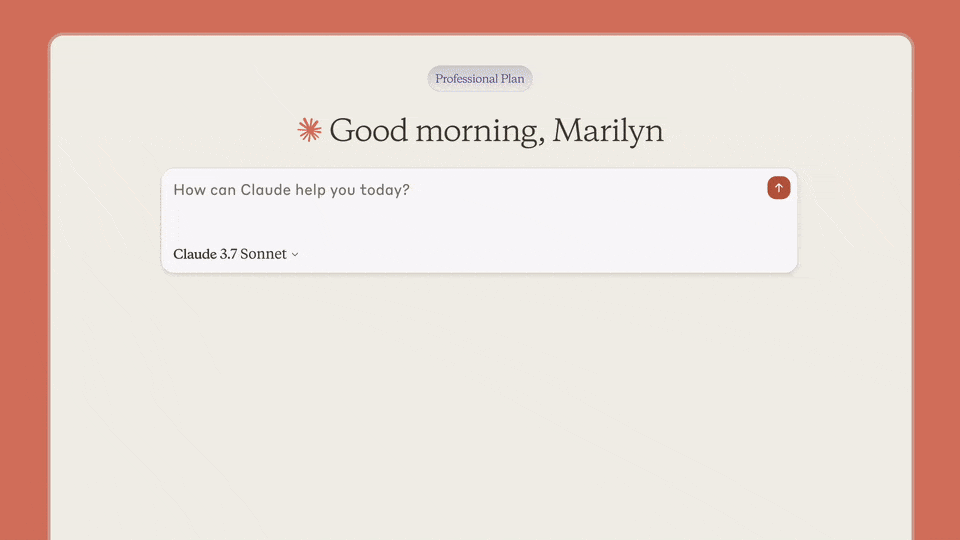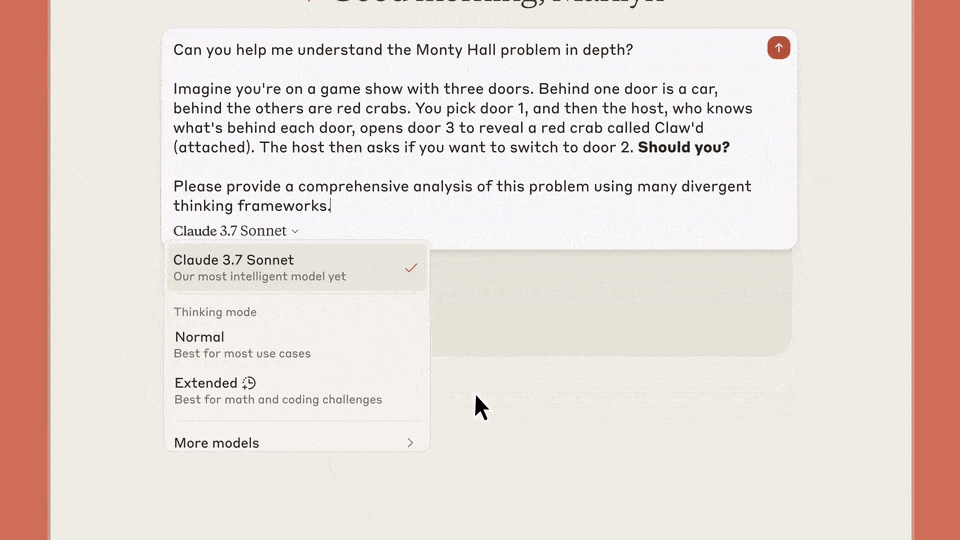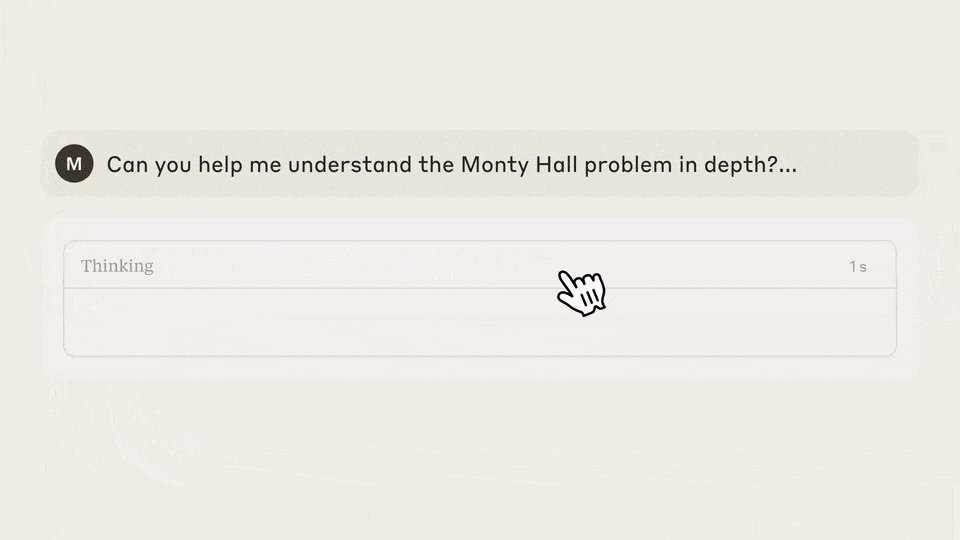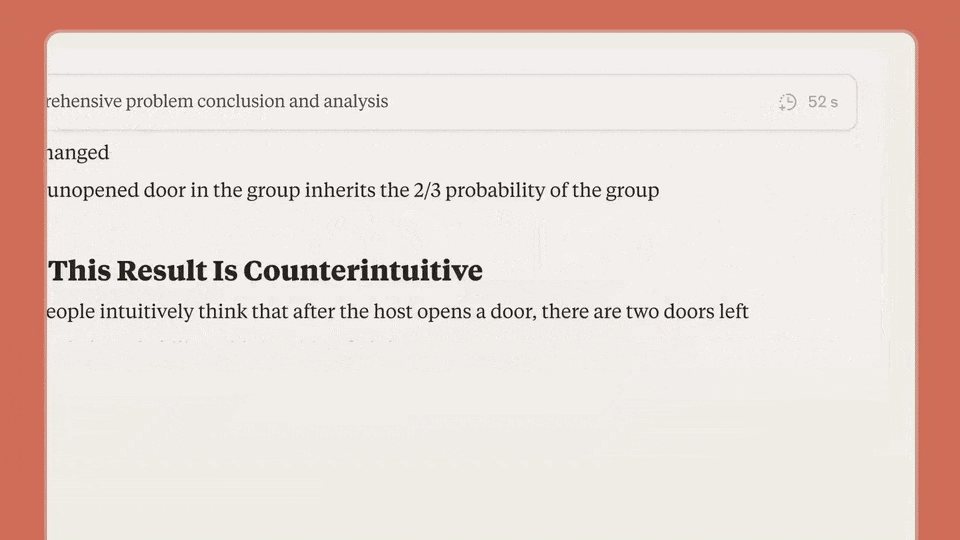
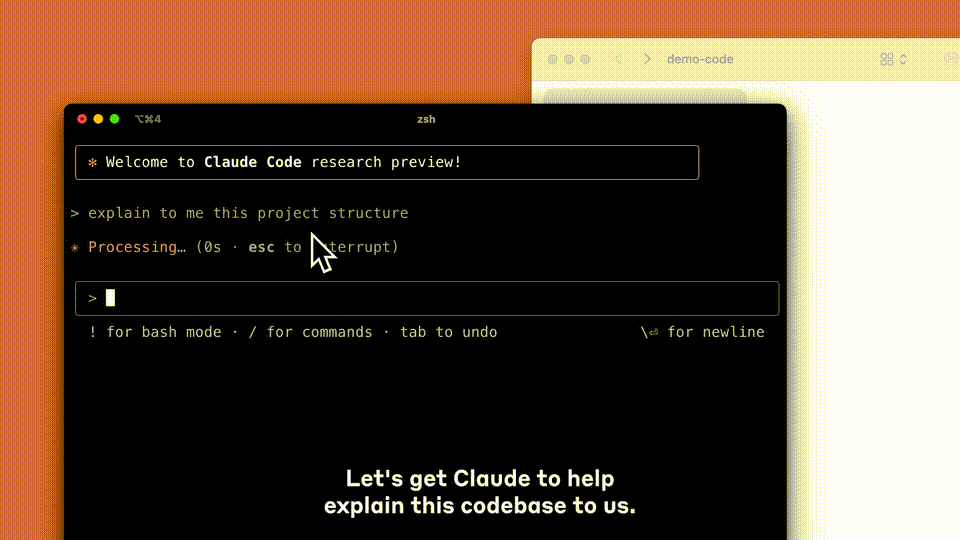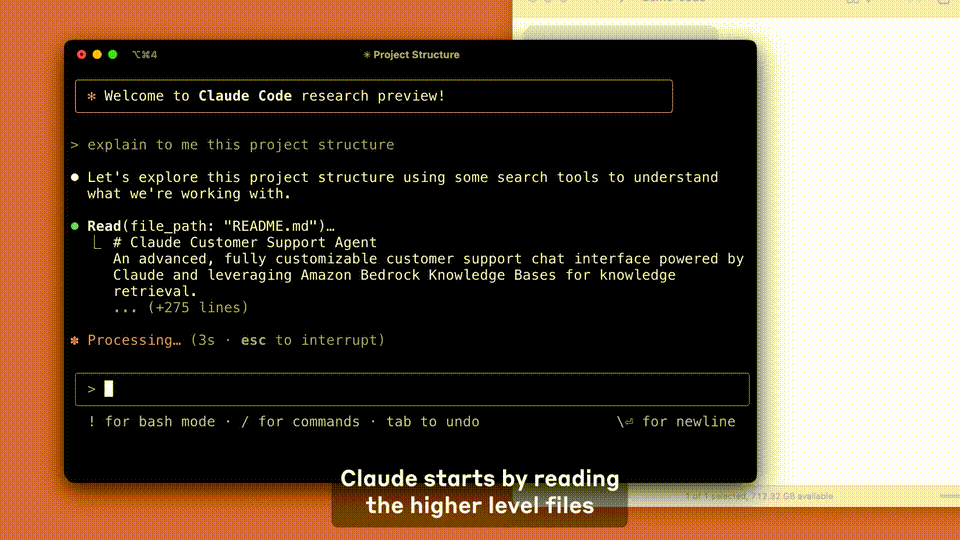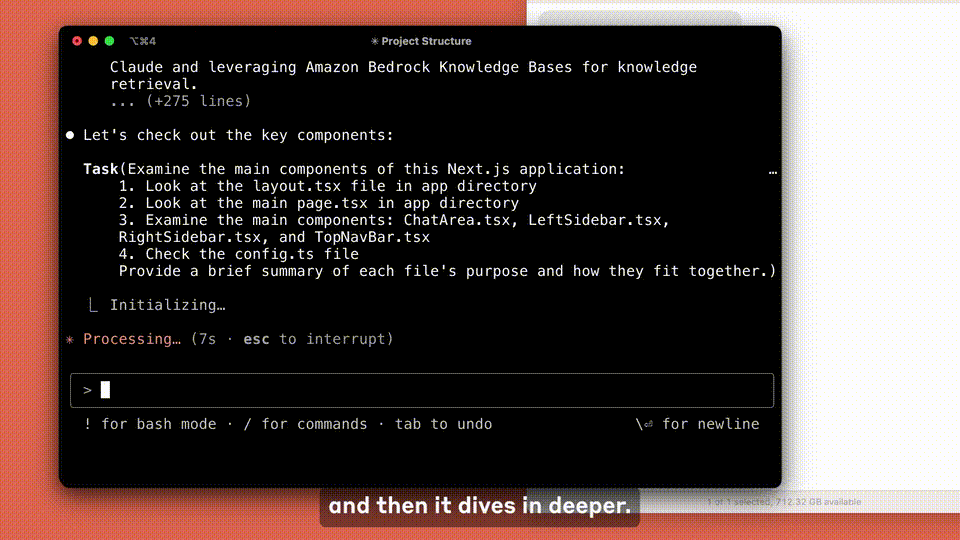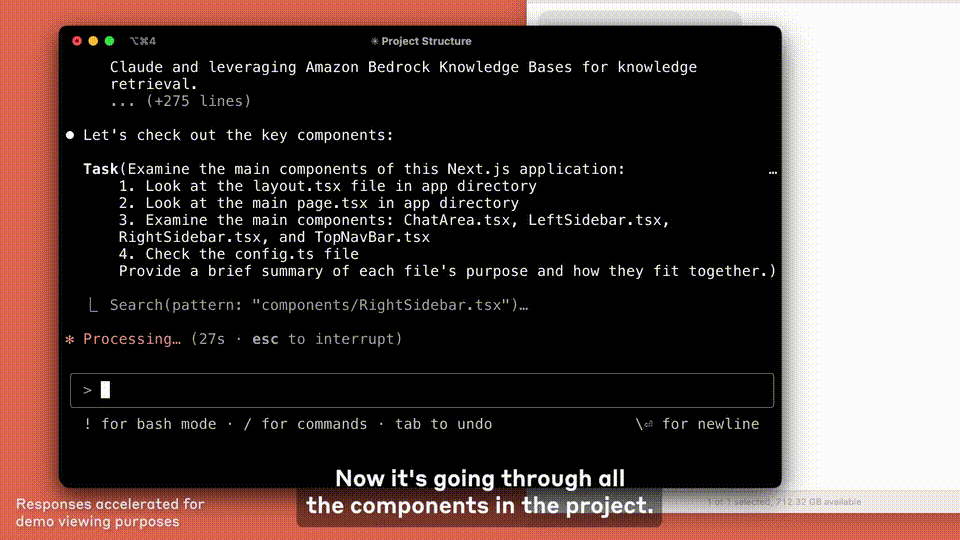
假定你想破解一个博弈论数常识题——蒙提霍尔问题,扔给Claude 3.7 Sonnet,然后同期采用「Extended」模式。
它便会展示详备CoT经过,用时52秒就完成了。
最要津的是,Claude 3.7 Sonnet目下总共东谈主免费可用,目下「膨大念念考」模式还莫得上线。
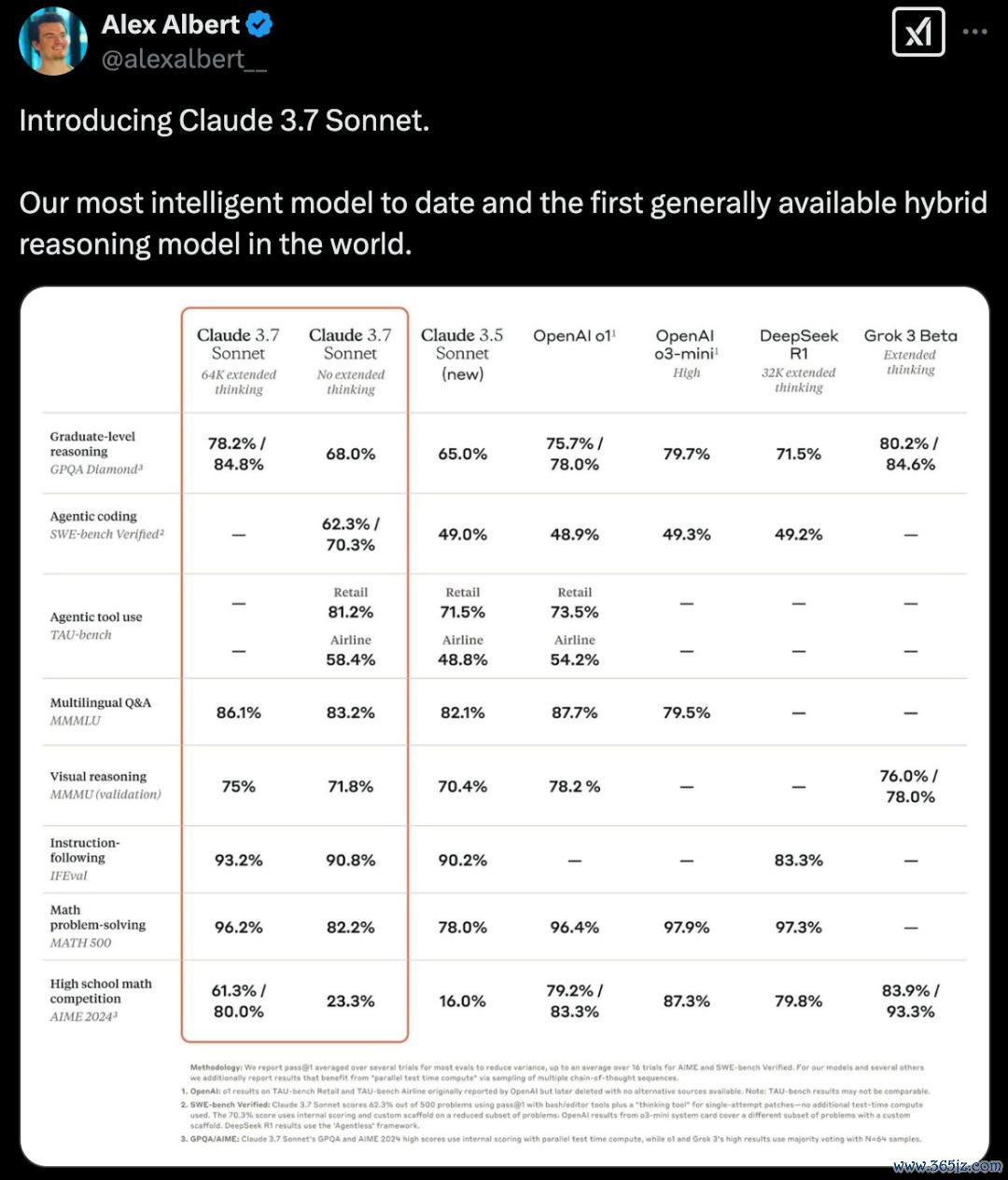
在多项基准测试中,「膨大念念考」模式加握下的Claude 3.7 Sonnet,在数学、物理、指示实践、编程等刷新SOTA。
相较于上一代Claude 3.5 Sonnet,数学、编码智商更是暴涨10%以上。
除了数学,Claude 3.7 Sonnet(64k extended thinking)确凿统统碾压o3-mini,DeepSeek R1,与Grok 3不相落魄。
API用户不错精准抑遏模子的念念考时辰
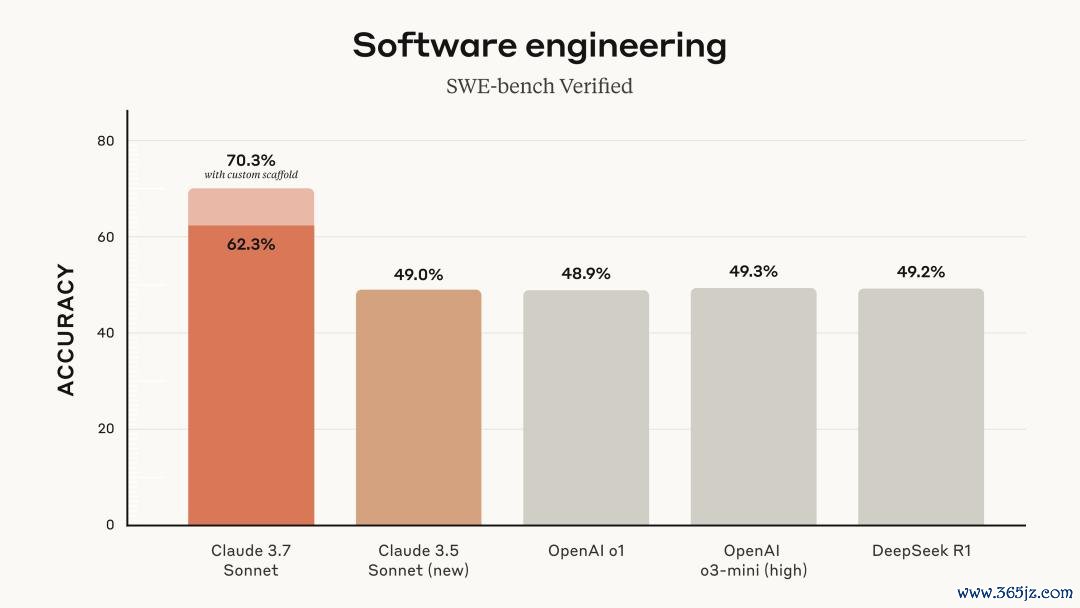
不错说,Claude 3.7 Sonnet统统是一个最强「软件工程AI」。在SWE-bench上,创下了70.3%的高分。
与此同期,首款「智能体编程」器具Claude Code(预览版)也在今天问世了。
如今,它也曾成为Anthropic里面,不行或缺的器具。在早期测试中,Claude一次性就完成东谈主类需要45分钟的任务。
也等于说,你作念居品司理,AI给你打工写代码。
虽莫得Claude 4,Anthropic这波出乎预料的顶住,实属给AI界又一震荡。
这半个月,注定是2025开年以来AI含金量最高的。
Grok 3上周刚发布,这周DeepSeek连气儿开源5天,OpenAI GPT-4.5据称也要上线,再加上Claude 3.7 Sonnet,大模子界限的混战又脱手了。

民众首款「混杂推理」模子出身
在官方博文中,Anthropic称,Claude 3.7 Sonnet是Anthropic迄今为止最智能的模子,亦然市集上首个混杂推理模子。
Claude 3.7 Sonnet省略产生确凿即时的响应或逐渐展示念念考经过的详备要领,这些要领对用户是可见的。API用户还不错概述抑遏模子的念念考时辰。
在编码和前端网页开发方面,Claude 3.7 Sonnet得到显贵进步。
除此以外,他们还推出了一款名为Claude Code的号召行器具,用于智能体编码。
目下,Claude Code仅算作有限的照拂预览版提供,它使开发东谈主员省略平直从他们的结尾将雄伟的工程任务交付给Claude。
推理,是一个LLM举座智商
Claude 3.7 Sonnet的遐想理念与市集上其他推理模子不同。
Anthropic笃信,就像东谈主类使用一个大脑来处理快速反应和深度念念考通常,推理当该是前沿模子的举座智商,而不是一个统统零丁的模子。这种长入的门径为用户提供了更通顺的体验。
Claude 3.7 Sonnet在几个方面体现了这一理念。
最初,Claude 3.7 Sonnet既是普通的言语模子(LLM),亦然一个推理模子:不错采用在什么时候但愿模子正常回应,什么时候但愿它在回应之前念念考更长的时辰。
在范例模式下,Claude 3.7 Sonnet是Claude 3.5 Sonnet的升级版块。
在膨大念念考模式下,它在回应之前进行自我反念念,这提高了在数学、物理、指示革职、编码和其他很多任务上的性能。
泛泛,两种模式对模子的辅导效果相似。
其次,通过API使用Claude 3.7 Sonnet时,用户还不错抑遏念念考的预算——
你不错告诉Claude在回当令最多念念考N个tokens,N的最大值为128K tokens的输出规定。这使得用户不错在速率(和老本)与回应质料之间进行权衡。
第三,在开发推理模子时,Anthropic在数学和料到机科学竞赛问题上的优化程度略微缩小,而是将重心转向了更能反应企业骨子使用LLM的实践寰宇任务。
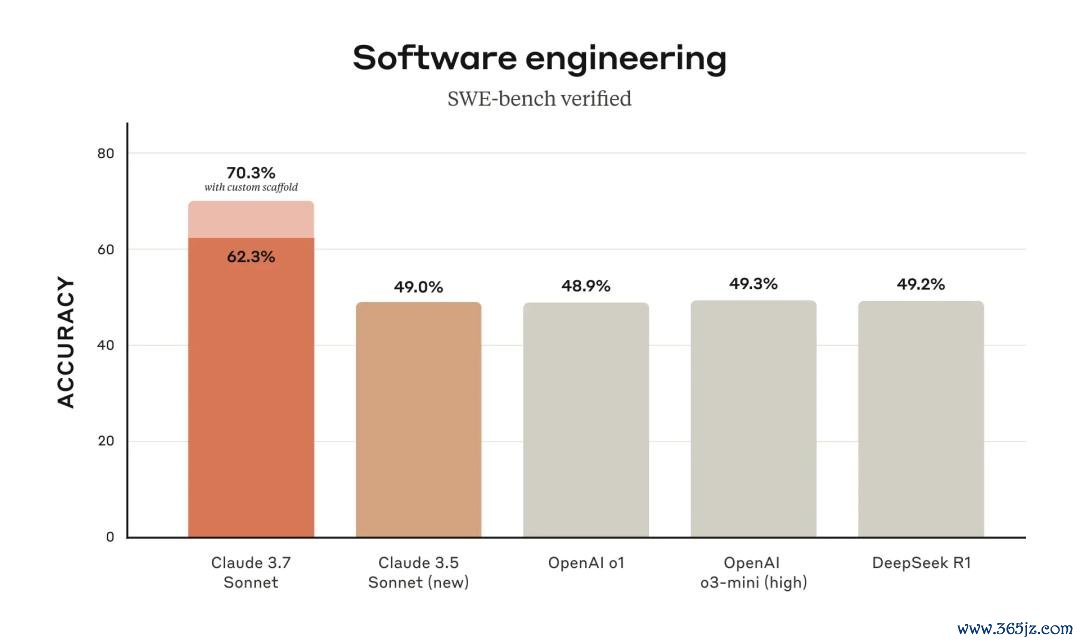
Claude 3.7 Sonnet在SWE-bench Verified上刷线SOTA,该评测旨在评估AI模子管束实践寰宇软件问题的智商
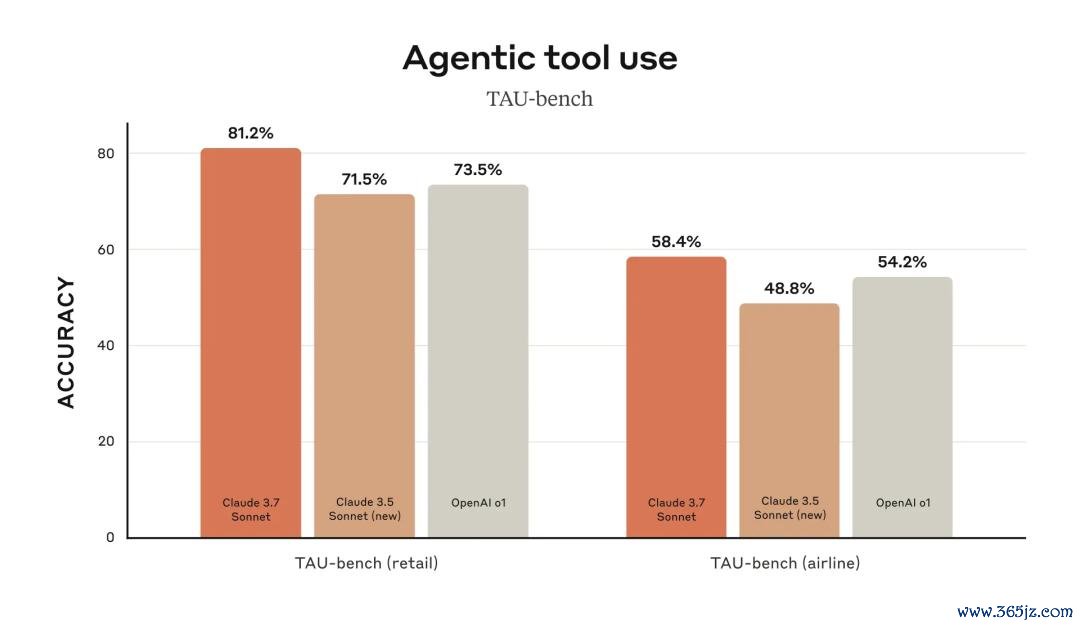
Claude 3.7 Sonnet在TAU-bench上刷新SOT,TAU-bench是一个测试AI智能体在复杂实践寰宇任务中与用户和器具交互智商的框架
如前所述,Claude 3.7 Sonnet确凿在各大基准测试中,性能得到了显贵进步。
相较于最新Grok 3 Beta模子,Claude 3.7 Sonnet(64k extended thinking)在推理方面确凿打成平手。而在数学、视觉推理方面,又略逊色于Grok 3 Beta。
与o3-mini、DeepSeek R1比拟,除了数学,带有膨大念念考模式的Claude 3.7 Sonnet拿下最高分。
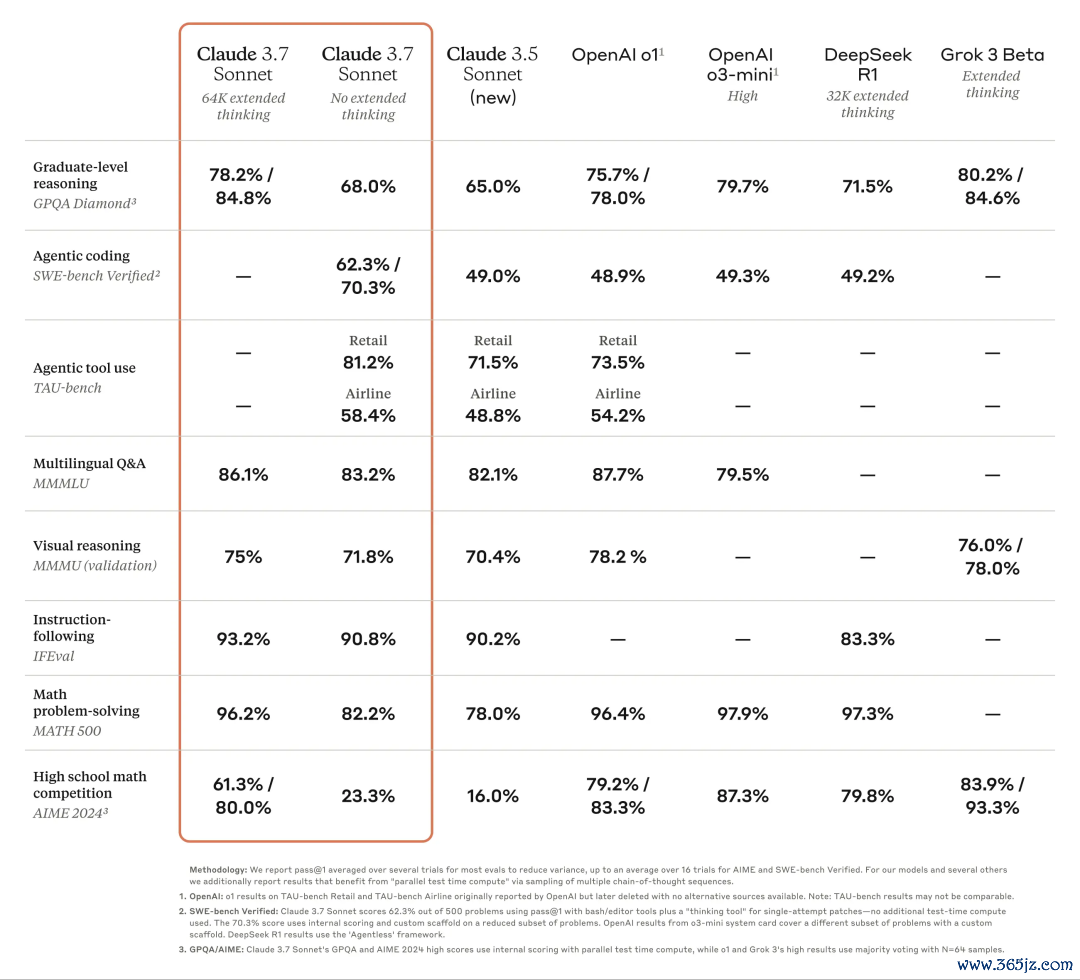
Claude 3.7 Sonnet在职务指示跟随、通用推理、多模态智商和自主编程方面推崇出色,膨大念念考模式在数学和科学界限带来了显贵进步。除了传统基准测试外,它以至在宝可梦游戏测试中稀奇了总共先前模子
AI编码智能体,一次完成45分钟任务
自2024年6月以来,Sonnet系列一直是民众开发者的首选模子。
今天,Anthropic的首个智能体编码器具Claude Code出身,目下以限量照拂预览的格式发布。
Claude Code主动与东谈主配合,省略搜索和阅读代码、裁剪文献、编写和运行测试、提交并将代码推送至GitHub,以及使用号召行器具——同期确保用户在每一步都能参与其中。
此外,本次更新还创新了Claude.ai上的编码体验。
目下,总共Claude套餐都因循GitHub集成——开发者省略将代码仓库平直集中到Claude。
算作Anthropic迄今为止最庞杂的编码模子,Claude 3.7 Sonnet能更深入地相识个东谈主样式、职责样式和开源样式,并一举成为开发bug、开发新功能以及编写GitHub文档的庞杂助手。
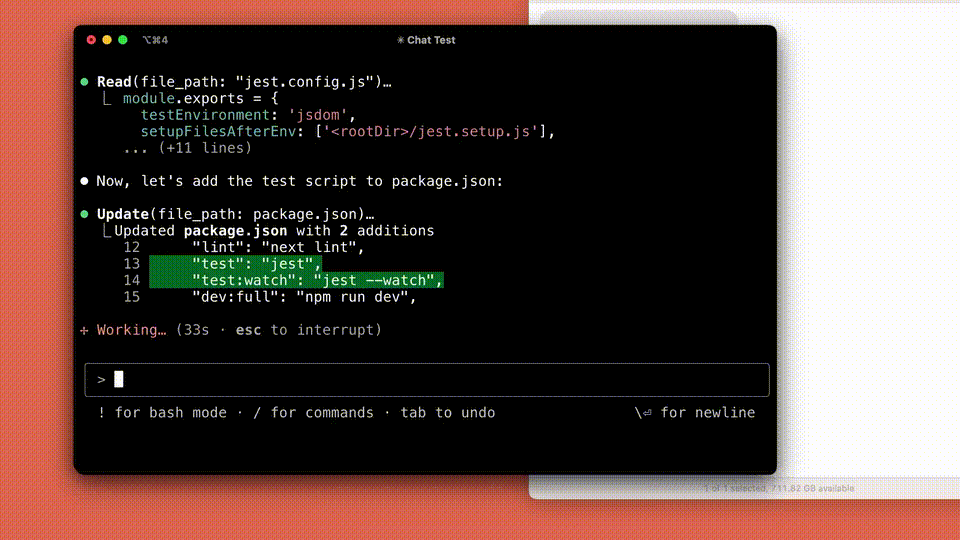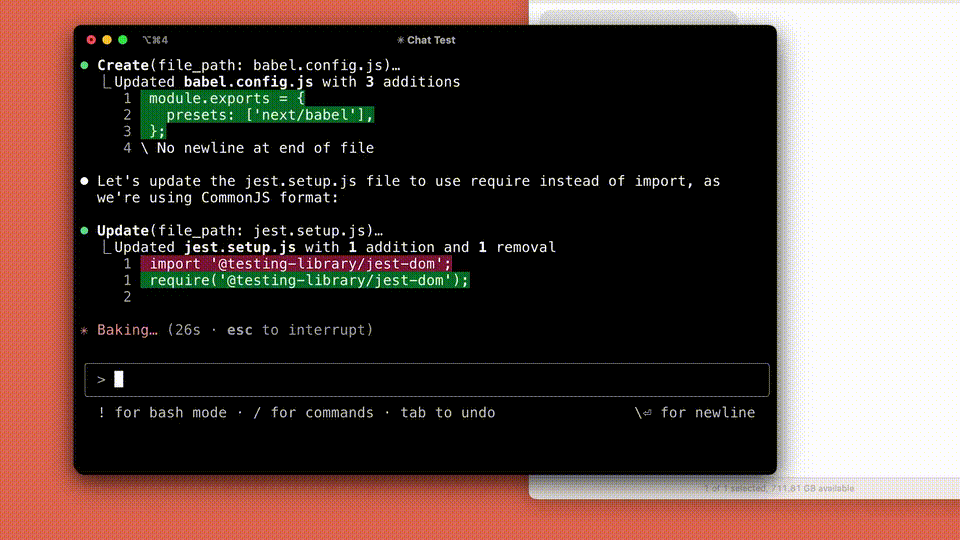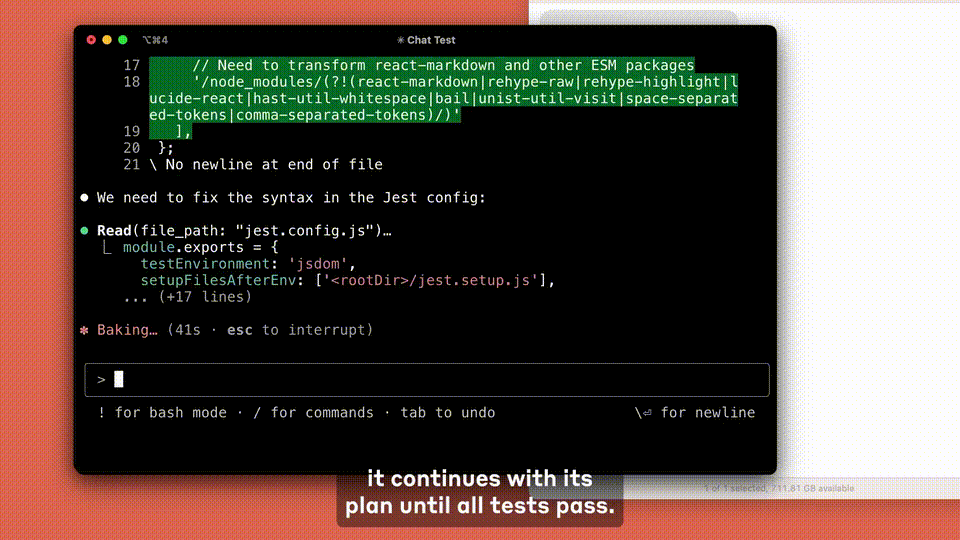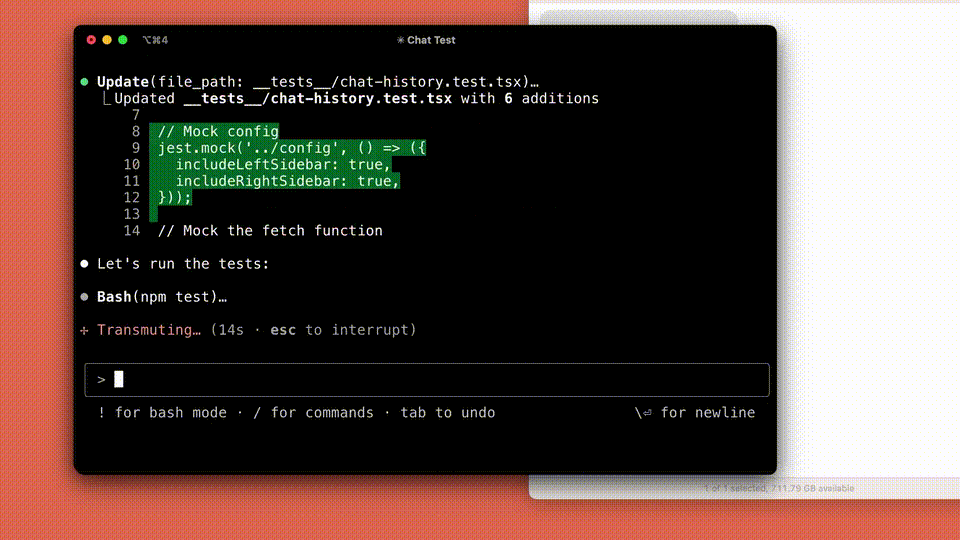
目下,Claude Code还处于早期阶段,但也曾成为Anthropic团队不行或缺的器具,尤其是在测试驱动开发、调试复杂问题和大界限重构方面。
在早期测试中,它省略一次性完成了泛泛需要手动职责45分钟以上的任务,显贵减少了开发时辰和职责量。
在接下来的几周里,Anthropic盘算凭据使用情况约束创新它:进步器具调用的可靠性、加多对万古辰运行号召的因循、创新应用内渲染效果,并膨大Claude对自己智商的相识。
全新的测试时Scaling

Claude算作AI智能体
Claude 3.7 Sonnet具备了一项被称为「行为膨大」(action scaling)的新特色——这种创新使其省略迭代调用函数、响应环境变化,并握续操作直到完成洞开式任务。
举例在料到机使用方面:Claude省略通过发出编造鼠标点击和键盘按键来代替用户完成任务。与前代比拟Claude 3.7 Sonnet省略在料到机使用任务中参加更多的交互次数,同期配备更填塞的时辰和料到资源,因此每每能取得更好的罢了。
这一越过在OSWorld评估中得到了充分体现,这是一个用于评估多模态AI智能体智商的测试平台。
Claude 3.7 Sonnet在启动阶段就展现出了较好的推崇,而跟着其握续与编造料到机交互,其性能上风还会随时辰推移而约束扩大。
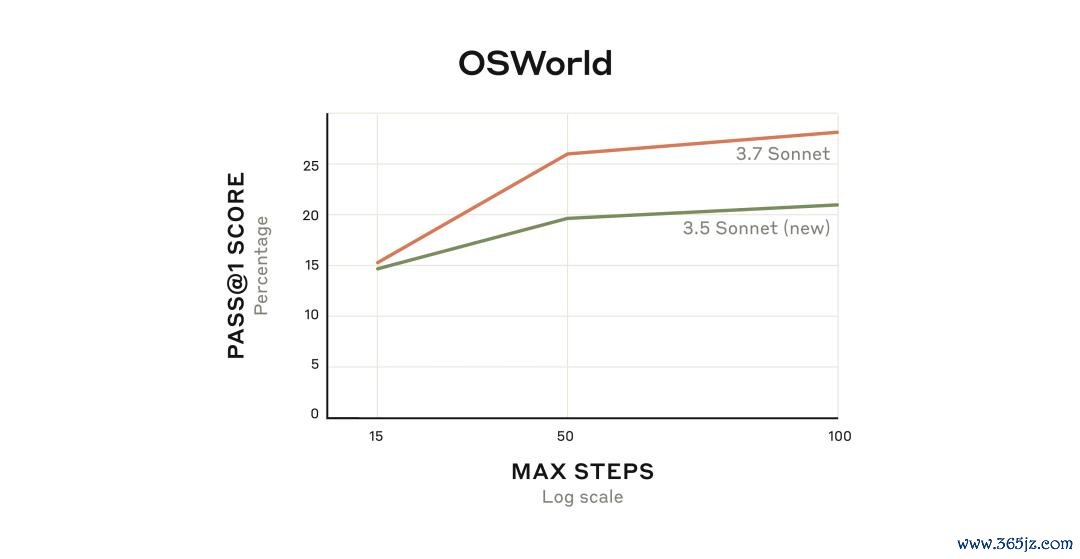
Claude的膨大念念考模式与AI智能体进修相谀媚,不仅匡助它在OSWorld等宽敞范例评估中取得了更好的推崇,还让它在一些其他出东谈主预料的任务中罢了了枢纽糟蹋。
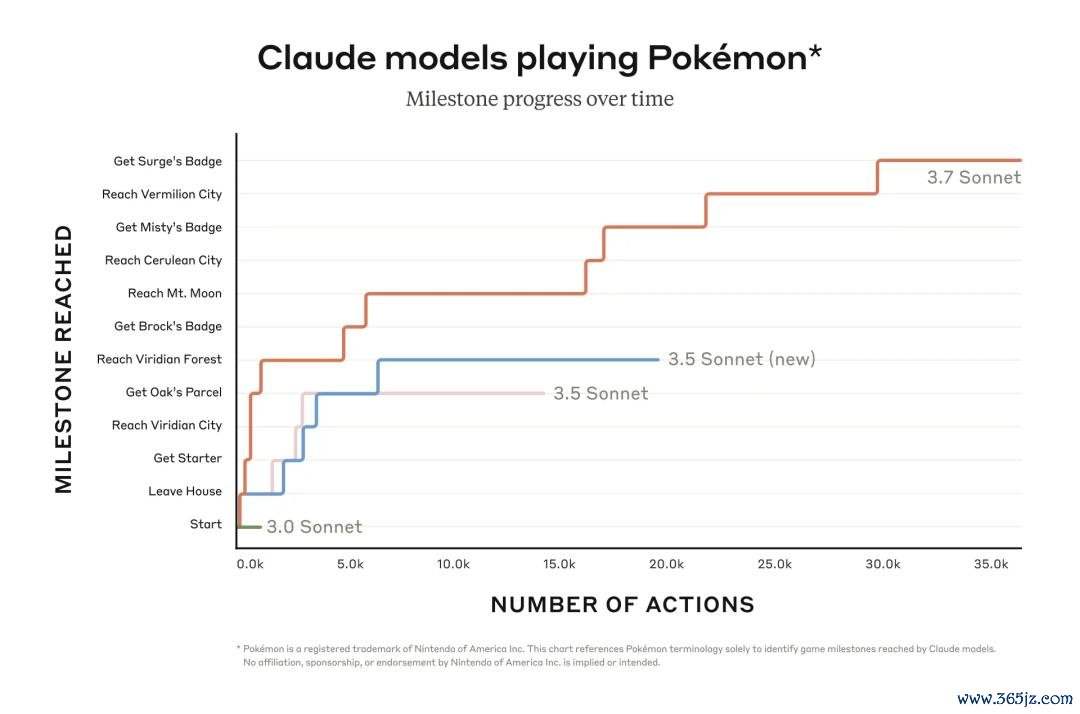
以玩游戏为例——相等是在Game Boy掌机经典游戏「口袋魔鬼:红」中的推崇。他们为Claude配备了基础回顾智商、屏幕像素输入功能,以及按键操作和屏幕导航的函数调用智商,使其省略糟蹋惯例落魄文规定,握续进行游戏,罢了长达数万次的握续交互。
鄙人图中,他们对比了具备膨大念念考智商的Claude 3.7 Sonnet与之前版块的Claude Sonnet在口袋魔鬼游戏中的进程。
如图所示,早期版块在游戏来源就难以鼓动,Claude 3.0 Sonnet以至无法走出故事开端真新镇的启动小屋。
而Claude 3.7 Sonnet凭借创新后的AI智能体智商取得了显贵进展,得胜挑战并打败了三位谈馆馆主,赢得了相应的徽章。
Claude 3.7 Sonnet在尝试多种战略和再行疑望既有假定方面推崇出色,这使它省略在游戏经过中约束进步自己智商。
串行与并行测试时料到Scaling
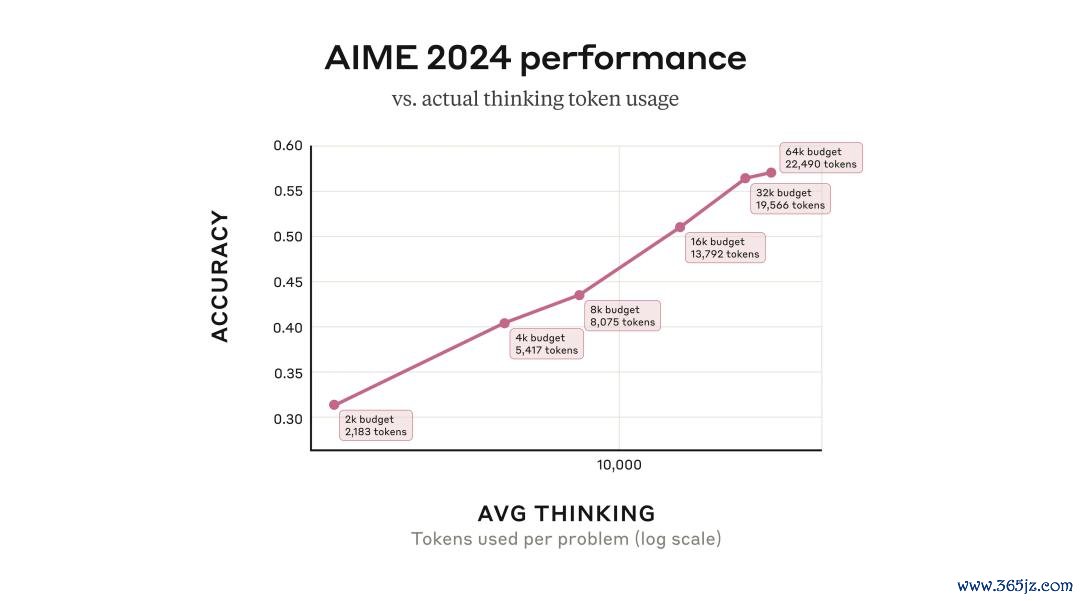
当Claude 3.7 Sonnet左右其膨大念念考智商时,不错说它利用了「串行测试时料到」机制。
具体而言,它会在生成最终输出之前,实践多个连气儿的推理要领,并在此经过中握续加多料到资源参加。
总体来看,这种机制省略以可量度的方式进步其性能推崇:举例,在数常识题求解方面,其准确率会跟着允许采样的「念念考Token」数目的加多呈对数增长。
Claude的照拂东谈主员还在探索使用并行测试时料到来进步模子性能。
具体门径是通过采样多个零丁的念念维经过,并在不事前知谈正确谜底的情况下采用最好罢了。这不错通过多数表决或共鸣投票机制来罢了,即采用出现频率最高的谜底算作「最好」谜底。
另外也不错使用另一个LLM来考证其职责罢了,或遴选经过进修的评分函数来采用最优谜底。
这些优化战略(及关联照拂职责)已在多个AI模子的评估报告中得到考证。
在GPQA评估中,他们通过并行测试时料到Scaling取得了糟蹋性进展。
具体而言,通过调用等同于256个零丁样本的料到资源,谀媚进修优化的评分模子,并配置最大64,000个Token的推理名额,Claude 3.7 Sonnet在GPQA测试中达到了84.8%的总体得分(其中物理学部分高达96.5%)。
值得扎眼的是,即使超出惯例多数表决的规定范围,模子性能仍在握续进步。
下图列出了评分模子门径和多数表决门径的详备罢了。
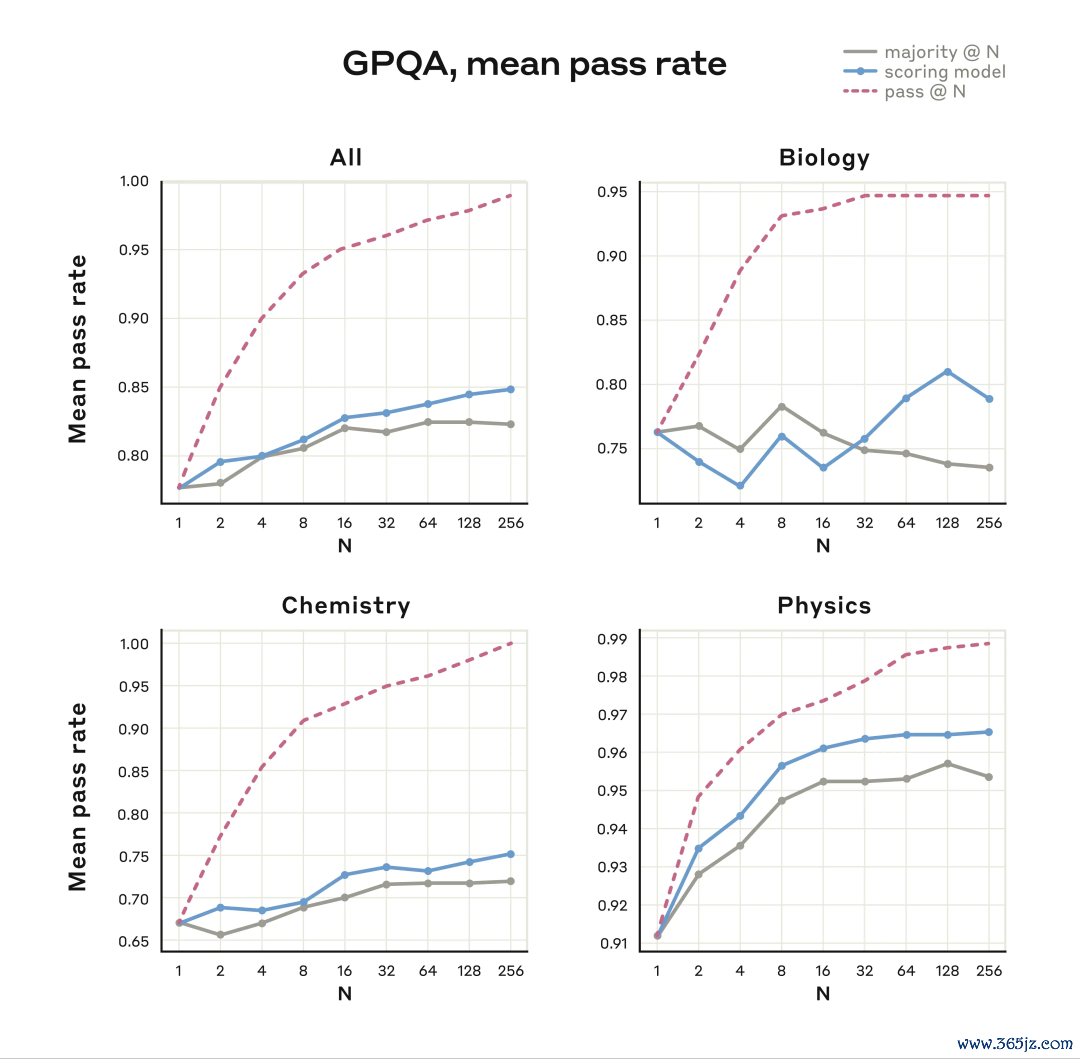
这些门径省略进步Claude回应的质料,况且泛泛无需恭候其完成推理经过。同期进行多个不同的深度念念维运算,Claude省略探索更多问题管束念念路,显贵进步正确谜底的输出频率。
三步道路图,Claude合作家已来
Claude 3.7 Sonnet和Claude Code象征着,向实在增强东谈主类智商的东谈主工智能系统迈出的紧迫一步。
凭借其深入推理、自主职责和灵验配合的智商,它们让咱们更接近一个畴昔,在哪里东谈主工智能丰富了东谈主类所能罢了的事情。
如今,Claude合作家已来。

最新版,不错免用度了
值得一提的是,Claude 3.7 Sonnet目下也曾在Claude.ai平台上线,Web、iOS和Android用户皆可免费体验。
对于但愿构建自界说AI管束决策的开发者,不错通过Anthropic API、Amazon Bedrock以及Google Cloud的Vertex AI进行看望。
在范例模式和膨大念念考模式下,Claude 3.7 Sonnet的价钱与其前代居品斟酌:3好意思元/百万输入token,15 好意思元/百万输出token ——这其中包括了念念考token的用度。
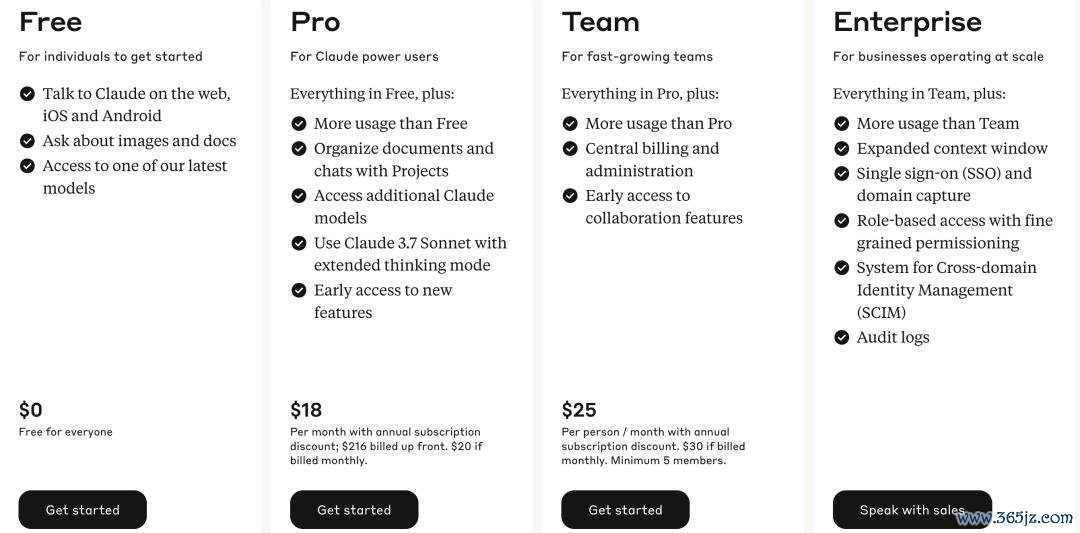
Anthropic套餐订价
AI大佬测试
宾夕法尼亚大学沃顿商学院的栽植Ethan Mollick也曾在畴昔几天对Claude 3.7进行了测试,
Claude 3.7每每给他带来与第一次使用ChatGPT-4时斟酌的嗅觉:既咋舌不已,又对它们的智商感到一点不安。以 Claude的原生编码智商为例,咱们目下不错通过当然对话或文档赢得可运行的范例,而无需任何编程技术。
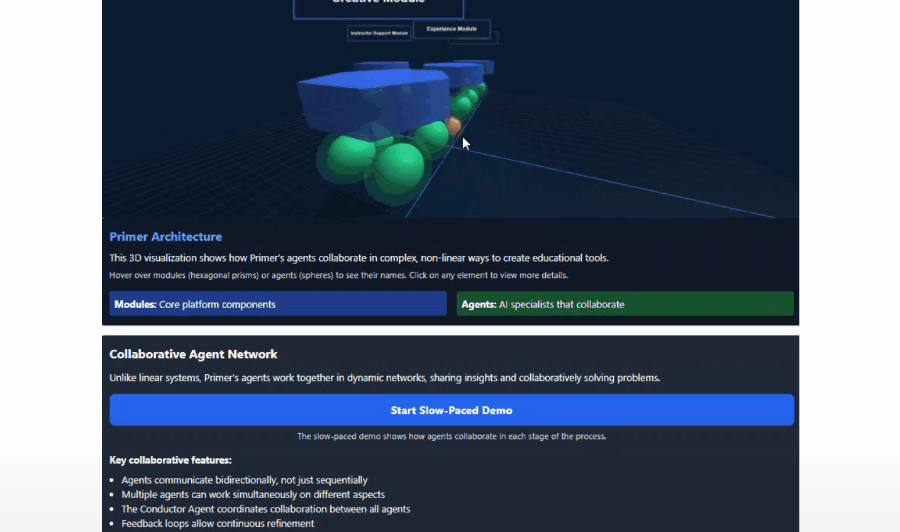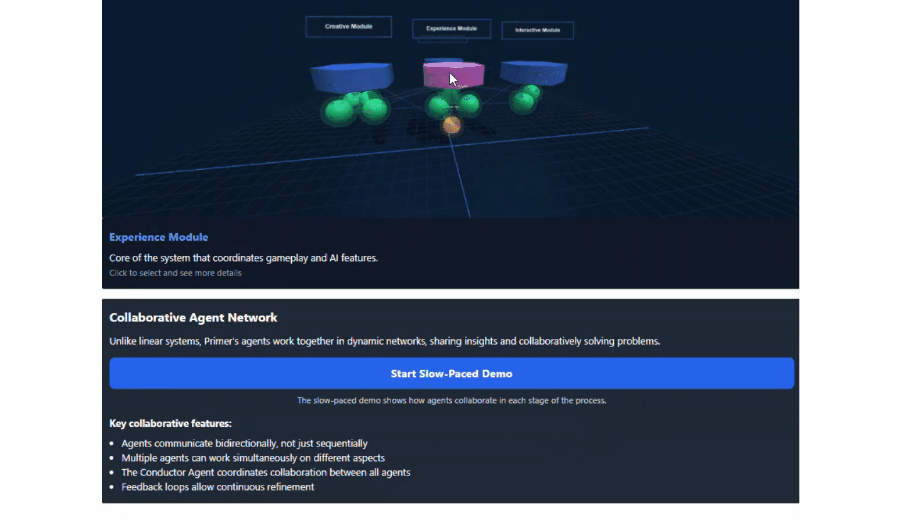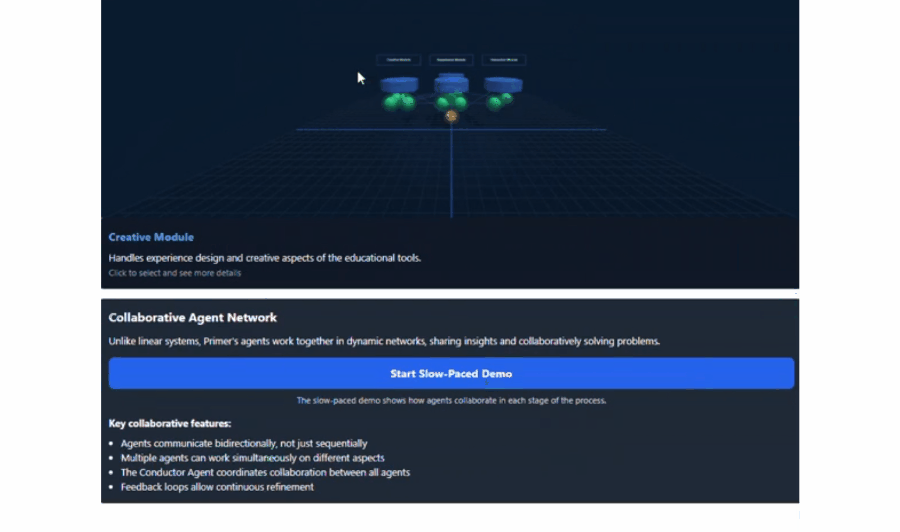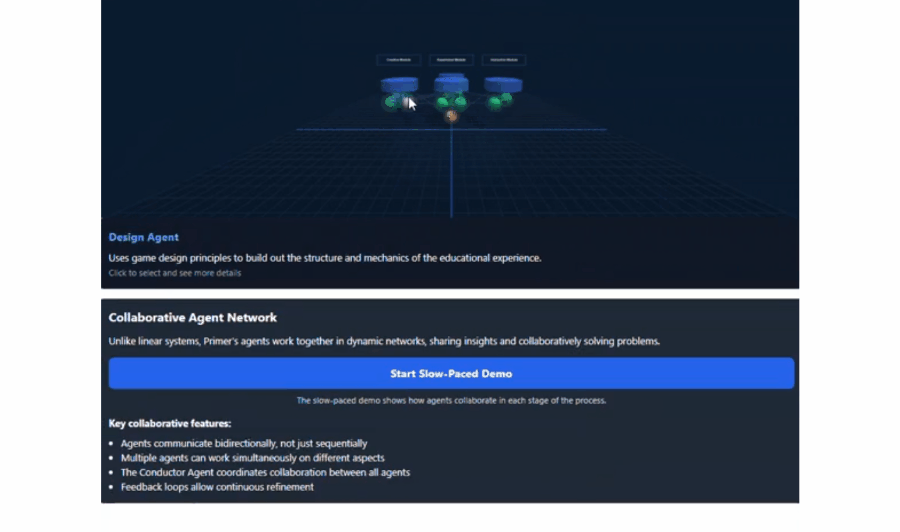
举例,他向Claude提供了一份对于新式AI栽植器具的提案,并在对话中条款它「以3D格式展示所建议的系统架构,并使其具有交互性」。罢了,它生成了咱们论文中中枢遐想的交互式可视化效果,莫得任何诞妄。
这些图形固然很纯粹,但并不是最令东谈主印象真切的部分。实在让东谈主咋舌的是,Claude自主决定将其制作成一个逐渐演示来评释关联见地,而这并不是咱们条款它作念的。
这种对需求的预判和对新门径的念念考是AI界限中的一项新糟蹋。
再举一个更道理道理的例子,Ethan Mollick告诉Claude:「给我作念一个交互式的时辰机器装配,让我不错穿越回畴昔,并发生一些道理道理的事情。挑选一些不寻常的时辰点让我且归...」 以及 「添加更多图像。」
只是这两条辅导之后欧洲杯体育,就出现了一个功能王人全的交互式体验,以至还配有简略但迷东谈主的像素图像(这些图像骨子上令东谈主骇怪地印象真切——AI必须使用纯代码「绘图」这些图像,而无法看到它正在创建的内容,就像一个被蒙住眼睛的艺术家。



